
作者|Taylor出品|芯片技术与工艺
当OpenAI的GPT-5在得克萨斯州的机房中昼夜轰鸣,当Nvdia的H200芯片被炒至数十万美元仍一卡难求,中国的算力芯片产业正站在一个历史性拐点——这不是一场匀速追赶的马拉松,而是一场从"生存"到"反超"的悬崖攀登。
#01 产业裂变:静悄悄的"算力革命"与结构性突破
2025年的中国AI芯片市场,正在上演一场"结构性质变",其剧烈程度远超表面数据。
根据中国信息通信研究院《算力发展指数白皮书》与IDC联合数据,中国AI芯片市场规模从2024年的210亿美元狂飙至380亿美元,其中国产芯片销售额从60亿美元激增至160亿美元,占比由29%跃升至42%,增速高达112%,是国外芯片增速的三倍有余。这不仅是数字的游戏,更是一场角色转换——国产芯片正从"应急备胎"变为"主力座舱"。
但更深层的变化在于技术代差的压缩。以FP16稠密算力为例,华为昇腾910C已达640-800 TFLOPS,虽与NvdiaH100的1979 TFLOPS仍有差距,但已从"代际鸿沟"缩小至"可控差距"。根据美国对外关系委员会(CFR)最新报告,若采用TP综合性能指标衡量,昇腾910C的TPP值约为12,032,而NvdiaH200高达15,832——差距虽存,但已非不可逾越。
然而,"训练抢海外、推理转国产"的市场分化已成为新常态。在万亿参数大模型训练场景中,系统级协同能力的短板会被指数级放大,国产芯片仍难撼Nvdia地位;但在智能驾驶、边缘计算等推理场景,国产化率已突破50%。这种"不对称突破"恰恰是中国算力芯片最现实的生存智慧——不在正面战场死磕,而是在游击战区建立根据地。

#02 江湖格局:三股势力、两条路线与一个底层逻辑
中国算力芯片的战场,从来不是单一赛道的线性竞赛,而是三股势力交织的生态博弈。其底层逻辑遵循一个铁律:硬件性能决定下限,软件生态决定上限,而场景定义生死。
第一梯队:体系化巨兽——华为的"全栈战争"
华为昇腾是这场战争中的"重装集团军",其杀手锏是全栈自研的达芬奇架构。与NvdiaCUDA的SIMT架构不同,达芬奇采用3D Cube矩阵计算单元,专为AI计算优化,在卷积、矩阵运算等场景能效比提升30%以上。昇腾910C不仅是一颗芯片,更是CANN异构计算架构+MindSpore AI框架+CloudMatrix集群系统的"算力矩阵"。
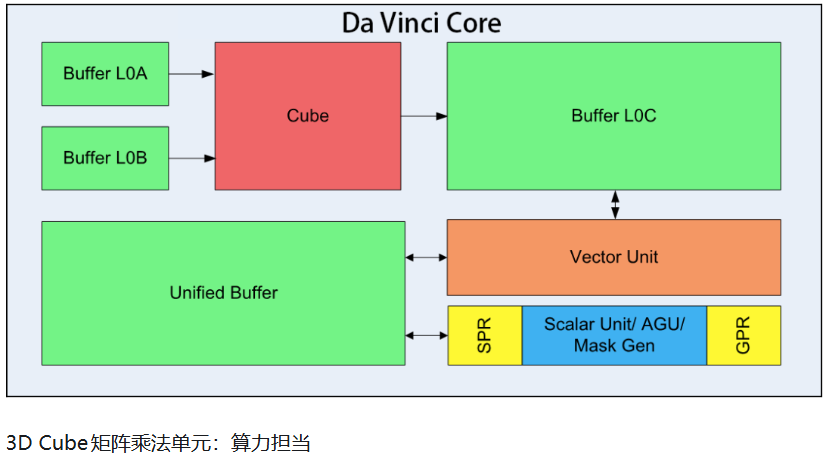
2024年,昇腾独占国产卡70%+市场份额,其CloudMatrix 384超节点实现300 PFLOPS算力,总内存容量与带宽分别是NvdiaGB200 NVL72的3.6倍和2.1倍。这种"体系化作战能力"让任何单点技术突破都难以撼动其地位。但CFR报告尖锐指出:华为的优势建立在封闭生态之上,其商业化进展受限,开发者社区规模仅为CUDA生态的不足1%。
第二梯队:技术孤勇者——寒武纪的"架构执念"
寒武纪像个"技术苦行僧"。陈天石、陈云霁兄弟2014年在国际权威期刊发表论文,定义了寒武纪芯片指令集,其MLUarch指令集与微架构完全自研,不依赖CUDA。思元590在FP8精度下的表现,甚至让部分开发者喊出"全村的希望"
但商业现实残酷:2024年寒武纪在中国市场份额仅1%,整体市占率0.16%。其困境在于:技术原创性未能转化为生态统治力。正如上海交通大学行业研究院报告所洞察,寒武纪"夹在Nvdia的标准霸权与华为的体系闭环之间,走一条孤勇者的生死线"。深度绑定BD等互联网客户虽带来短期订单,却难以构建像CUDA那样的开发者"护城河"。
第三梯队:兼容派"特洛伊木马"——海光与摩尔线程的"渐进革命"
海光信息的深算DCU、摩尔线程的MUSA架构,深谙商业真理:打不过标准,就先拥抱标准。海光DCU兼容CUDA生态,在商业银行批量应用,其深算二号性能较一号提升100%,下一代深算三号进展顺利。摩尔线程通过CUDA兼容层降低迁移成本,2024年收入4.4亿元,2025年上半年已达7亿元,科创板IPO已过会。
但兼容路线的天花板同样明显:壁仞科技2024年在中国通用GPU市场份额仅0.2%。这就像在别人的地基上盖房子,建得再漂亮,也随时可能被"断水断电"。
#03 技术暗战:三条"破局之路"的底层逻辑
芯片产业的残酷在于,性能差距可以追赶,生态差距却需要十年之功。国产芯片的真正较量,发生在三个看不见硝烟的战场,每个战场都关乎底层技术路线的选择。
战场一:存算一体——突破"内存墙"的理论最优解
传统冯·诺依曼架构中,数据在存储与计算单元间搬运消耗了90%的能耗与延迟,这就是"内存墙"难题。清华大学《人工智能芯片技术白皮书》指出,存算一体技术CIM(ComputingIn-Memory)通过在存储单元中集成计算功能,将能效比提升10-100倍。
华为、寒武纪均已布局存算一体专利,但量产节点仍不明朗。国外Lightmatter公司已推出光子计算芯片,用光代替电子传输数据,试图"终结AI能耗危机"。这场竞赛的难点不在理论,而在工艺实现与生态适配。当整个AI软件栈都为冯·诺依曼架构优化时,颠覆性架构面临的是"鸡生蛋还是蛋生鸡"的困境。
战场二:ChiplChiplet异构集成——绕开光刻机的"曲线救国"
当摩尔定律在3nm节点气喘吁吁,Chiplet技术将大片芯片拆分为多个小芯粒,通过先进封装"拼"出高性能。NvdiaGB200、AMD MI300已采用CPU+GPU Chiplet方案,国产厂商中,MetaX率先实现Chiplet封装量产。
但Chiplet不是魔法。CFR报告尖锐指出:先进封装依赖的半导体制造设备EV光刻机、TSMCCoWoS工艺,同样在美国管制清单上,不过已经又国内突破。这不过是将"制造难题"转化为"封装难题",而封装的核心设备依然卡在别人手里。更关键的是,Chiplet的互连标准(如UCIe)仍由Intel、AMD等主导,国产芯片面临"标准二次卡脖子"风险。
战场三:软件生态——从"代码迁移"到"开发者心智"的终极战争
这是最残酷的现实:CUDA生态覆盖95%的AI框架,国产MindSpore兼容率约70%,而寒武纪的BANG语言、壁仞的BIRENSUPA,开发者社区规模不足CUDA的千分之一。
ETO团队研究发现,中国学者在神经形态计算、光学计算等领域的论文数量全球领先,但在谷歌学术引用中,最大比例(41%)仍来自美国。这说明:技术影响力不等于生态控制力。一个AI博士五年时间都在CUDA上写代码,他的肌肉记忆、思维习惯、社交网络全系于Nvdia。改变一代开发者的心智,需要不止一代人的时间。
#04 使用场景:算力需求的分化与收敛
芯片的价值最终由场景定义。2025年的算力需求呈现训练场景集中化、推理场景碎片化、边缘场景垂直化三大特征。
场景一:数据中心大模型训练——"暴力美学"的算力黑洞
万亿参数模型训练需要千卡级集群协同,通信效率、内存带宽、系统稳定性成为比单卡算力更关键的指标。NvdiaH200凭借NVLink 4.0互联与HBM3e内存(带宽1.2TB/s),在系统级TPP指标上实现碾压。华为CloudMatrix虽通过暴力堆叠实现总内存领先,但在跨节点通信效率与软件调度成熟度上仍有差距。
场景二:智驾与边缘推理——"实时响应"的低延迟战场
自动驾驶L4级需要<10ms的端到端延迟,算力密度与功耗平衡成为核心。寒武纪MLU370系列在推理效率上表现突出,华为Hi3559-AV100安防芯片支持实时视频结构化处理。边缘场景对CUDA生态依赖度低,为国产ASIC芯片打开空间:燧原科技2024年出货1.3万张推理卡,切入中小AI企业。
场景三:移动终端与消费级AI——"极致能效"的功耗战争
手机SoC中的NPU需在1W功耗内实现30 TOPS算力。AppleA12 Neural Engine、华为麒麟990通过异构计算架构将AI任务卸载至专用单元。这类场景强调软硬件协同优化,国产芯片在移动端几乎空白,但RISC-V+AI加速器的组合或成未来突破口。
#05 国家意志:一场不能输的"算力主权"战争
2025中国算力大会上,工信部明确将GPU芯片列为"关键核心技术"攻关目标。这不是产业建议,而是最高层级的战略动员。
"东数西算"工程已接入10个省区市平台,累计沉淀数十亿条算力监测数据,构建起国家级的"算力调度网"。欧盟《芯片法案》与美国《CHIPS法案》的出台,标志着算力竞争已上升为国家安全议题。中国信通院数据显示,2024年中国智能算力规模达190亿美元,占全球23.3%,但核心芯片自给率不足30%。
国家队的入场方式很微妙:不做裁判,只做"超级用户"。政务云、智慧城市、科研院所的订单,成了国产芯片的"战略缓冲带"。2024年,华为昇腾70%的营收来自政府与国企采购。但这种"内循环"也暗藏风险——当芯片可以靠政企关系而非性能指标销售,谁还有动力去挑战CUDA这座大山?
#06 未来十年:三个"生死命题"的哲学思辨
站在2025年展望,中国算力芯片产业必须回答三个决定命运的命题:
命题一:自主可控vs国际兼容——"忒修斯之船"的芯片版本
华为的全栈自研是理想主义者的"长征",寒武纪的兼容路线是现实主义者的"缓称王"。真正的答案或许是:在底层架构坚持自主,在接口层拥抱兼容。就像龙芯LoongArch通过二进制翻译运行为x86应用——既要造自己的轮子,也要能装上别人的轮胎。
这背后是更深层的哲学选择:算力主权是否意味着必须排斥全球协作?历史告诉我们,闭关自守从未带来技术领先。如何在"安全底线"与"开放创新"间找到动态平衡,考验的不仅是技术能力,更是战略智慧。
命题二:通用GPU vs专用ASIC——"瑞士军刀"与"手术刀"之争
大模型训练对算力的需求呈现"暴力美学",但推理场景正在碎片化。 一个GPU打天下的时代正在终结 ——自驾需要低延迟手术刀,物联网需要低功耗柳叶刀,科学计算需要高精度金刚钻。
这为国产芯片提供了战略窗口:深耕垂直领域的"小巨人"可能比"全能选手"活得更好。谷歌TPU在推荐场景击败GPU已证明,场景定义架构,而非架构定义场景。字节跳动大规模采购寒武纪、阿里平头哥自研"真武PPU",正是这一逻辑的应验。
命题三:资本狂欢vs长期主义——"死亡谷"的幸存者法则
摩尔线程122倍市盈率、寒武纪千亿市值——国产芯片正经历"情绪溢价"的泡沫期。但历史反复证明:芯片产业没有捷径,只有十年如一日的研发投入与生态建设。
SemiAnalysis报告指出,Nvdia的领先地位不仅在于硬件,更在于其构建的"全栈式"硬件集成与软件生态。Nvdia市值登顶建立在三十年CUDA积累之上,每年研发投入超百亿美元。相比之下,寒武纪2024年研发费用仅28亿元,却支撑7nm制程、自研指令集、全栈软件三层创新,这种"以一当十"的模式不可持续。
穿越"死亡谷"的唯一路径是:找到付费场景→实现正向现金流→反哺研发→扩大生态。燧原科技切入中小AI企业实现年度盈利,证明商业闭环比技术先进性更重要。
#07 哲学沉思:在"有限游戏"与"无限游戏"之间
"万物得其本者生,百事得其道者成。"
中国算力芯片的突围,本质是一场"有限游戏"与"无限游戏"的选择。有限游戏的规则是:在Nvdia定义的赛道里,用CUDA的语法,争取更高的算力、更低的功耗、更便宜的价格。这是一场注定艰难的追赶,因为领跑者可以随时修改终点线。
无限游戏的规则是:重新定义问题本身。当存算一体突破内存墙,当Chiplet绕开光刻机,当RISC-V+AI加速器重构移动端生态——我们不是在追赶Nvdia,而是在创造下一个Nvdia。
这个过程注定孤独。陈天石曾说:"我们上市不是为了融资,是为了证明给中国芯片看:原创路线也能走通。"这句话的悲壮在于:他不仅要打败对手,还要战胜环境。
但历史总是奖励"无限游戏"的玩家。正如华为在5G标准制定中从追随者变为引领者,正如中国光伏产业从"骗补"到制霸全球——当自主创新的"本"与产业规律的"道"合一时,万物自会生长。
结语:在算力之巅,看见未来的形状
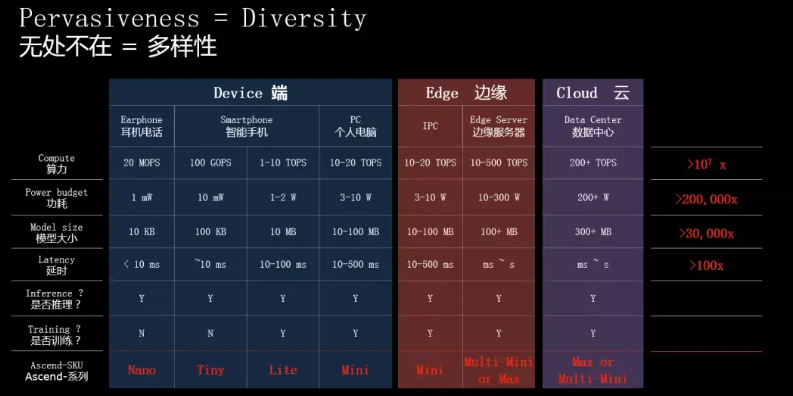
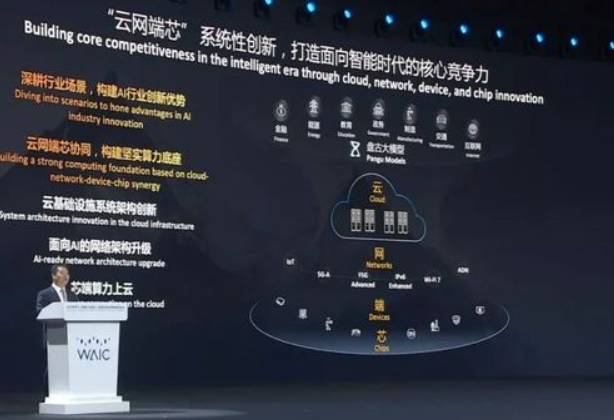
2025年的中国算力芯片产业,像一株在岩缝中生长的松树——根系深扎在政务云、智能驾驶、边缘计算的缝隙里,枝叶却努力伸向通用计算的苍穹。阿里的云网端芯,更是系统性创新,
这不是一场百米冲刺,而是一场持续十年的"战略耐力赛"。短期的市场份额、技术代差、估值泡沫,都只是漫长征途上的驿站。真正的终点,是当中国开发者用中文写AI框架,当全球模型在昇腾芯片上训练,当"算力主权"不再是一个需要论证的命题。
"世界上只有一种真正的英雄主义,那就是认清生活的真相后依然热爱生活。"送给所有在中国算力芯片战场上的"孤勇者"——你们正在做的,是定义下一个十年中国科技天花板的事。
这注定艰难,但值得。
数据来源与核心参考文献:
1.中国信息通信研究院《中国算力发展报告(2024年)》
2. IDC《中国人工智能计算力发展评估报告》
3.美国对外关系委员会(CFR)《China's AI Chip Deficit》
4. SemiAnalysis多数据中心训练报告
5.清华大学《人工智能芯片技术白皮书》
6.上海交通大学行业研究院《算力产业研究报告》
7.各公司财报、招股书及工信部公开数据
8.学术论文:Vaswani et al. "Attention is all you need", Sevilla et al. "Compute Trends"